
虚拟机的组成
- 编译器 把程序员编写的代码转化成字节码文件
- 类加载器 把字节码文件加载到运行时数据区
- 执行引擎(垃圾回收器、及时编译器、解释器
- 本地方法
字节码文件
字节码文件就是.class文件
文件组成:文件头(判断文件类型)、属性、常量、静态变量
i++/++i istore
类的生命周期
编译、加载、检查、链接、初始化???
final修饰的附上初值
在什么时候会初始化?
类的回收(垃圾回收机制
类加载器
启动类加载器
应用程序加载器
版本
双亲委派机制
如何打破双亲委派机制:自定义加载器???
优缺点:避免重复加载,安全///
场景
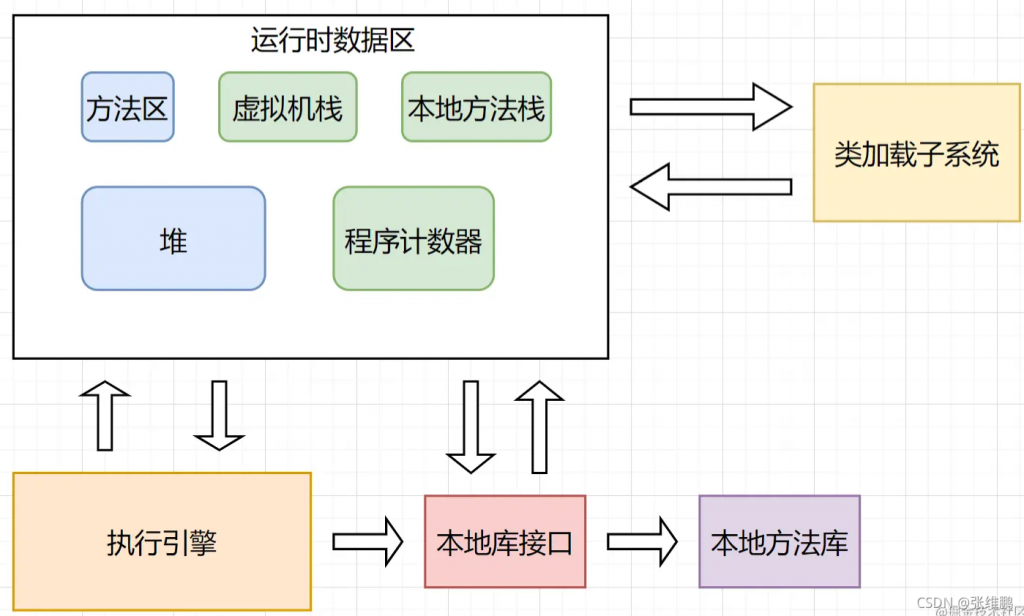
运行时数据区
栈
一个线程 分配一个栈
私有区
- 虚拟机栈
- 本地方法栈
堆
对象 常量池 字符串常量池
方法区
xxxx
直接内存
什么时候申请直接内存
释放
程序计数器
私有
垃圾回收
java是自动垃圾回收
方法区回收
一般不需要回收。JSP等技术会通过回收类加载器去回收方法区中的类。
堆内存的回收
- 引用技术法
xxx
- 可达性分析法
软引用
常用于缓存,若内存不足,会先回收软引用
软引用的使用于回收???
SoftReference提供了一套队列机制
–>也看了好几遍 创建的软引用的引用放到 集合里面 不让回收, 内存被回收的放到队列里,使用的时候得去集合遍历 不为空的才可用
–>这里的意思是如果堆内存不够,会把软引用的空间释放掉,但是软引用这个对象你还没释放,如果用置null的方式,如果没回收那就搞错了
–>Java提供一个机制,就是构造软引用的时候传一个队列进去,当哪个软引用空间被释放的时候,就会把引用对象放进队列,这时候可以通过队列元素置null来实现释放
队列总结:软引用空间置null,队列对象置null
软引用的使用场景-缓存
如果软引用对象被回收那么这个对象k-v的hashcode也应该被回收
软引用总结
软引用相对于强引用是一种比较弱的引用关系,如果一个对象只有软引用关联到它,当程序内存不足时就会将软引用的数据进行回收
弱引用
一般不使用,与软引用基本一致。回收也要用队列
与软引用的差别:不管内存够不够都要回收!!
虚引用和终结器引用
- 开发中不会使用
- 虚引用:释放申请的直接内存
- 终结器引用:一个对象被回收时 放在队列里 后执行finalize方法,第二次被回收时才会真正被回收(绑定强引用自救???
强引用
最常见的方式。通过可达性算法来判断。
- 垃圾回收算法
1.找到存活对象
2.回收不再存活的对象
标记-清除算法 两个阶段。第一阶段从GCRoot对象开始使用可达性分析法遍历 第二阶段就是删除(每个要维护一个标志为 缺点:内存碎片+分配速度慢(要遍历空闲链表,容易不满足要求而遍历到最后
复制算法 堆空间=From+To 每次分配对象只能使用其中一块 1.将GCRoot和GCRoot关联的对象搬运到To 然后清除From 互换空间名字 优点:吞吐高+无碎片化 缺点:内存利用低
标记-整理算法:标记后将存活的移动到一起,然后再清理 优点:无碎片化+内存利用率高 缺点:整理慢,遍历次数多(整理算法)
分代GC:Young区(Eden+S0+S1) + Old区 伊甸区:对象刚出生的时候放的地方 Y区指存活时间短的对象
-XX:+UserSeialGC//手动指定垃圾回收器
memory //arthas命令
-xms //堆最小>1mb
-xmx //堆最大 >2mb
-xmm //新生代的大小(老年代可计算)
-XX:SurvivorRatio //Eden与(S1+S0)的比例–>对象回收执行流程:伊甸园要满的时候MinorGC/Young GC==》回收的回收,余下的放在S1 执行复制算法 s1与s0 to与from==》互换再执行复制算法 最后对象到了s0 gc一次年龄+1,最大年龄15==》晋升老年代 ==》老年代又满了(年轻代满了也minorGC不了,也会放入老年代)先尝试minor GC 还是不足 触发Full GC(stw) ==》 还是不足out of memory异常
–>为什么分代!有些很快就会被回收+老年代存长期存活的(bean)+新生代<<老年代
–>优点:可以设置比例+两代可以设置不同的垃圾回收算法+基本不用FullGC而是minorGC stw减少
*STW:停滞的过程 GC线程有部分阶段需要停止所有的用户线程 所以STW越短越好 一个场景,用户在下单刚好遇到程序垃圾回收导致下单失败
回收算法评判标准
1.吞吐量(执行用户代码时间/cpu总执行时间)越高,垃圾回收效率越高。
2.最大暂停时间 越小越好
3.堆使用效率 标记清除算法优于复制算法 前者可用堆大
*三种不能兼得 堆越大 暂停时间越长 减少暂停时间会降低吞吐量
*不同的场景下,使用不同的垃圾回收算法
垃圾回收器
垃圾回收器的组合关系 3种组合关系、G1

- 组合1
年轻代-Seria
特点:单线程 复制算法
优点:单CPU吞吐量出色
缺点:多CPU就不行了
老年代-SeriaOld
标记整理算法
其余同上
- 组合2
年轻代-ParNew
特点:多线程 复制算法
缺点:吞吐量和停顿时间不如G1
老年代-CMS
特点:标记-清除算法 关注暂停时间-可以并行
缺点:内存碎片问题+退化(内存不足)+浮动垃圾(并发清理阶段)吞吐量会下降
适用:大系统 高请求
步骤:初始标记+并发标记+重新标记+并发清理
- 组合3
年轻代-Parallel Scavenge
特点:复制算法
优点:吞吐量高 动态调参
缺点:不能保证单次停顿时间
场景:后台任务 大数据大文件处理
允许用户设置最大暂停时间
老年代-P O
特点:标记-整理算法
优点:并发,高效率,多核CPU
缺点:暂停时间长
场景:与P C配套使用
在使用组合3的时候最好不设置堆内存的最大值 会动态调整
- G1
G1之前内存是连续的。而G1是零散分布开来的,每个单位区称之为Region范围是1~32m。(画外音:有端联想>闪闪的儿科医生 头骨塑形手术术式 对头骨进行切割后的样子
Region:eden+old+survivor三个区 区域不是连续的
流程:新创建的在eden区 阈值60% 产生YoungGC(会记录耗时)、标记E和S区存活的、将存活的放在新的S区,年龄+1、后续再发生YoungGC就再搬运、多次搬运>=15会放入old区
*若一个对象大小>1/2(region)直接放入老年代的Humongous
若总共到达阈值45% 触发MixedGC
混合回收流程:初始标记、并发标记、最终标记、并发清理
与CMS不一样!!!!
- 初始标记 标记GCRoots引用的对象为存活
- 并发标记 第一次标记的对象引用的对象
- 最终标记 不同之处(只标记漏掉的标记,不管新创建的,不再关联的对象(比CMS快
- 并发复制清理 复制 没有内存碎片
选择存活率低的区域回收 G1
没有空区域用来复制 清理就会出现Full GC 单线程编辑-整理算法影响效率 要避免这种情况出现
jdk9之后建议使用G1 jdk8之前不成熟
优点:延迟可控、没有内存碎片、并发标记算法效率高SATB优于CMS
适用于较大的堆

发表回复