
sql基础
安装
在Linux系统下 mysql的安装 、文件配置、常用命令等
Linux常用命令详述见文章(Linux–常用命令篇)
建议使用FinalShell工具连接服务器,具体操作见文章
主要步骤大致分为:
- 检查MariaDB 它与Mysql会有冲突
- 检查是否已经存在MySQL服务
- 官网下载安装包
- 上传下载好的文件(SSH工具,可视化界面上传文件
- 进入/usr/local解压
- 创建data目录
- 创建MySQL用户组和用户
- 更改权限
- 配置环境 my.cnf文件
- 初始化
- 加入系统服务
- 启动服务,修改密码
- 配置远程访问
- 使用可视化连接工具(Navicat)测试连接
基本语句
详尽版访问文章
DDL数据定义
show databases;
create database base_name;
create database base_name if not exists base_name;
use base_name;
select database();
show tables;
desc table_name;
create table tb_user (
id int,
username varchar(20),
password varchar(32)
);DML数据操作(增删改
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);
DELETE FROM table_name WHERE condition;
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;DQL数据查询
SELECT column1, column2 FROM table_name WHERE condition;
##关于函数的使用
SELECT column1, COUNT(*) FROM table_name GROUP BY column1;
SELECT * FROM table_name ORDER BY column1;
SELECT * FROM table_name LIMIT 10;DCL数据控制
*左连接
*右连接
视图
view 可见数据范围是从其他表选择性、过滤和计算得到的(横向与纵向范围)它是一个虚拟的表
*视图本身不存储数据
WITH CHECK OPTION约束:
LOCAL:表示更新视图时只要满足该视图本身定义的条件即可。
CASCADED:表示更新视图时需要满足所有相关视图和表的条件。没有指明时,该参数为默认值。!!不仅会检查当前视图,还会检查它所依赖的视图对于可以执行DML操作的视图,定义时可以带上WITH CHECK OPTION约束
**作用:对视图所做的DML操作的结果,不能违反视图的WHERE条件的限制。保证更新视图是在该视图的权限范围之内。
若是继承的语句,会向上判断视图条件的范围
能够保护数据安全,可操作范围受到限制,不同的用户
业务场景描述:
信息重组适应业务场景
安全性需要
兼容老数据库
触发器
存储过程
事务
事务是一个原子性的操作,若在执行过程中出现问题 那么会回滚
事务有手动提交和自动提交 默认是自动提交
ACID事务的四个特性:
在sql高级详细解释
- 原子性 失败会回滚 依据的日志是Undolog
- 一致性 数据库的完整性没有被破坏 原子性和隔离性,对一致性有着至关重要的影响。
- 隔离性 不同的隔离级别有(1.读未提交ReadUncommit2.读已提交ReadCommit3.可重复读RepeatableRead4.可串行化读Serializable) 一次解决了 脏读 不可重复读 幻读的问题
- 脏读:前后select不一致 是B事务读到了A事务中还修改了但还未提交的数据
- 不可重复读:在一个相对庞大的事务A中,在不同时段对一条数据进行读操作,而此条数据在B事务中的修改已经提交。所以 在事务A中的两次读数据,结果会不一样 侧重点在读
- 幻读:幻影数据 select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。而不是指两次数据集不一样 因为在可重复读的级别下,在事务A中我两次判断有没有一个数据时候时,都会得到没有。但实际插入数据时,事务B的数据插入已经提交,造成了冲突,事务A插入数据失败
- 持久性 当事务操作完成后,数据会被刷新到磁盘永久保存,即便是系统故障也不会丢失。binlog 日志不会立即删除
sql高级
sql执行流程
1.一条sql语句 机器是看不懂的,所以有解析器
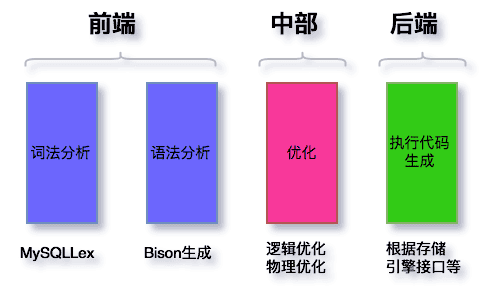
2.预处理器会判断表和字段是否存在
3.现在机器能看懂指令 要给你的语句做优化 MySQL查询优化器
优化原则为IO成本和CPU成本:MySQL 优化器 会计算 「IO 成本 + CPU」 成本最小的那个索引来执行
4.查询优化器会使用执行器去调用存储引擎的接口
接下来让我们详细了解存储引擎
存储引擎详述
mysql默认的存储引擎为InnoDB,其它的还有MyISAM
我们详细介绍InnoDB:
文件物理结构
- MyISAM:每个MyISAM表在磁盘上通常存储为三个文件:
.frm文件:存储表定义。.MYD文件:存储数据(MYData)。.MYI文件:存储索引(MYIndex)。
- InnoDB:InnoDB表的数据和索引存储方式较为灵活,可以配置为共享表空间或独立表空间:
- 共享表空间:所有InnoDB表的数据和索引都存储在系统表空间中,通常包括
ibdata1、ibdata2等文件。 - 独立表空间:每个表的数据和索引存储在单独的
.ibd文件中,这是通过设置innodb_file_per_table选项实现的。此外,InnoDB还有.frm文件存储表定义。
- 共享表空间:所有InnoDB表的数据和索引都存储在系统表空间中,通常包括
BufferPool
Buffer Pool (缓冲池)是 InnoDB 存储引擎中非常重要的内存结构,类似 Redis,起到一个缓存的作用
如果没有这个 Buffer Pool 那么我们每次的数据库请求都会磁盘中查找,这样必然会存在 IO 操作
第一次在查询的时候会将查询的结果存到 Buffer Pool 中,这样后面再有请求的时候就会先从缓冲池中去查询,如果没有再去磁盘中查找,然后在放到 Buffer Pool 中
*LRU算法:采用变种LRU算法解决了预读失效和缓冲池污染的问题
redis中的LRU:内存淘汰策略
Redo Log Buffer与Redo Log
buffer pool断电丢失怎么办。数据还没有刷入到磁盘(IO线程来完成),但又不能随时都在刷,会影响磁盘IO
都要刷入到磁盘,有什么区别吗?
1.随机IO与顺序IO
2.整页刷入与文件追加
redolog包含的是 表空间+数据页号+偏移量+修改的数据 由redologblock满了之后再写道磁盘。n个redologblock组成了redologbuffer
1)如果写入 redo log buffer 的日志已经占据了总容量的一半,此时就会把它们刷入到磁盘文件里;
2)一个事务提交的时候,必须把它的那些 redo log 所在的 redo log block 都刷入到磁盘文件里去。只有这样,当事务提交之后,修改的数据才不会丢失,因为 redo log 里有重做日志,随时可以恢复事务做的修改;
3)后台线程定时刷新,有一个后台线程每隔 1 秒就会把 redo log buffer 里的 redo log block 刷到磁盘文件里去;
4)MySQL 关闭的时候,redo log block 都会刷入到磁盘里去;
undolog
*undolog也要redolog进行持久化保护
是Innodb存储引擎层生成的日志。用于实现事务的原子性、MVCC机制的实现
与redolog不同的是,它记录逻辑操作,在恢复时逆向操作表数据以达到初始状态。
结构上InnoDB对undo log的管理采用段的方式,也就是回滚段(rollback segment)
undo log 的数据默认在系统表空间 ibdata1 文件中。
类别上分为两种一种是insert一种是update|二者区别主要在于用途和生命周期
*insert:记录insert的反向操作 即删除。它仅对进行插入操作的事务本身可见。在事务提交之后立即删除。不进行purge操作。
*update:它记录了对现有数据有影响的操作delete和update操作。并且在事务提交之后不会立即删除。会进入到historylist中等待purge线程做最后的删除操作。
*什么是purge:一个删除不需要的undolog日志的线程。MySQL提供了选项来控制Purge操作的速度,例如通设置innodb_purge_batch_size
change buffer(写缓冲
!只应用在非唯一普通索引、没有在buffer pool、进行了增删改操作的情况下
如果索引设置了唯一(unique)属性,在进行修改操作时,InnoDB必须进行唯一性检查。
体现在,进行满足以上条件的操作时,不会立即进行磁盘随机IO读取,仅仅记录buffer pool缓存的变更 等到未来读取这些数据的时候,再将数据merge恢复到缓冲池
应用场景:
(1)数据库大部分是非唯一索引;
(2)业务是写多读少,或者不是写后立刻读取;
脏页的处理
自适应刷脏
InnoDB与MyISAM的区别是什么
InnoDB和MyISAM是MySQL数据库中的两种不同的存储引擎,它们在功能和性能上有许多不同之处。以下是InnoDB和MyISAM的一些主要区别:
- 事务支持:
- InnoDB:支持事务处理,具有提交(commit)和回滚(rollback)能力。
- MyISAM:不支持事务处理。
- 锁机制:
- InnoDB:支持行级锁,适合高并发环境。
- MyISAM:支持表级锁,不适合高并发环境。
- 崩溃恢复:
- InnoDB:具有崩溃恢复能力,使用redo log保证事务日志的持久性。
- MyISAM:没有崩溃恢复能力。
- 外键约束:
- InnoDB:支持外键约束。
- MyISAM:不支持外键约束。
- 索引类型:
- InnoDB:使用聚簇索引,数据和索引存储在一起。
- MyISAM:使用非聚簇索引,索引和数据分开存储。
- 文件存储结构:
- InnoDB:数据和索引存储在系统表空间(如
ibdata1)和可能的独立表空间(.ibd文件)中。 - MyISAM:每个表的数据存储在
.MYD文件中,索引存储在.MYI文件中。
- 缓冲池:
- InnoDB:使用缓冲池(Buffer Pool)来缓存数据和索引页,提高访问速度。
- MyISAM:使用键缓存(Key Cache)来缓存索引页。
- 自适应哈希索引:
- InnoDB:支持自适应哈希索引,可以动态地为热点数据创建哈希索引以加速查询。
- MyISAM:不支持自适应哈希索引。
- 数据完整性:
- InnoDB:提供数据完整性保证,如原子性、一致性、隔离性和持久性(ACID)。
- MyISAM:不提供数据完整性保证。
- 存储限制:
- InnoDB:没有文件大小限制。
- MyISAM:有文件大小限制,但这个限制通常足够大,对于大多数应用来说不是问题。
- 全文索引:
- InnoDB:不支持FULLTEXT类型的索引。
- MyISAM:支持FULLTEXT类型的索引。
- 默认存储引擎:
- InnoDB:从MySQL 5.5.5开始,成为默认的存储引擎。
- MyISAM:在MySQL 5.5.5之前是默认的存储引擎。
- 备份和恢复:
- InnoDB:可以使用热备份,因为支持在线备份。
- MyISAM:通常需要关闭表进行备份,不支持热备份。
- CPU使用率:
- InnoDB:通常在高并发事务处理时,CPU使用率较低。
- MyISAM:在高并发事务处理时,CPU使用率可能较高。
这些区别使得InnoDB和MyISAM适用于不同类型的应用场景。InnoDB更适合需要事务支持、高并发和数据完整性保证的应用,而MyISAM则适合读多写少的场景,尤其是在MySQL 5.5.5之前的版本中。
索引
索引背景
演变历史,为什么这么变化,每一个的优缺点是什么?*注意是在MYSQL下而不是单纯这种数据结构的优缺点
数组–>链表–>二叉树–>平衡二叉树–>b树(每个节点储存了多个元素)–>b+树
解决了:内存占用大,查找耗时,结构退化,IO次数多,范围查找
b+树:数据在叶子节点:区,页,段
优化后 只在叶子结点中存储数据,其他节点只存储关键字,叶子结点之间通过双向指针关联

b树与b+树的区别
一种结构
b树的每一个节点都有数据
而b+树只有叶子节点会有数据
发表回复