
MQ基础
同步调用
余额支付例子:
劣势:拓展性差、性能下降、级联失败
优势:时效性强
异步调用
- 消息发送者:调用方
- 消息代理:管理、暂存、转发
- 消息接收者:服务提供方
优点:解除耦合,拓展性强、无需等待、性能好、故障隔离、缓存消息,流量削峰减谷
劣势:依赖Broker的可靠性、不确定下游业务是否成功、不能立即得到结果,时效性差
MQ技术选型
MessageQueue 消息队列–>broker
先进先出,有序
Rabbit、Active、Rocket、Kafka
RabbitMQ
整体架构与核心概念:
控制台端口和消息发送接收端口两个
publisher、consumer、(queue、exchange)–>broker
VirtualHosts隔离作用
入门:
exchange是负责路由转发消息,没有存储的功能
exchange与queue要绑定
可以一对多转发
数据隔离:
virtual host
Admin:用户、虚拟主机
客户端JAVA操作:
入门:
AMQP:消息通信协议,与语言无关、跨语言
SpringAMQP:一套API规范,一个实现spring-rabbit,调用API即可
*案例一(没有exchange:
- 引入依赖、控制台创建队列
- spring配置文件设置rabbitmq参数–自动连接
- RabbitTemplate工具类 .convertAndSend(queue_name,message)
- 接收监听消息使用 @RabbitListener(queues=”queue_name”)
*案例二(多个消费者绑定一个queue work模型
两监听者处理消息的速度不同
listener1 1 3 5 7 9
listener2 2 4 6 8 10
一人一个但是速度又不一样,默认轮巡处理,设置prefetch=1
listener1 1 2 3 4 5 6 8 9 10 11…
listener2 7 12…
**同一条消息只会被一个消费者处理
如果消息越来越多堆积,加多个消费者
交换机:
会需要exchange的。不是直接送到队列。
类型:1.fanout 2.direct 3.topic
Fanout
广播模式:分发给每一个队列。
两个fanout.queue监听器
testSendFanout是发送给交换机而不是发送给队列了
Direct–按需投放
不同的微服务收到不同的消息。direct会根据规则路由到指定的queue。
queue有不同的bindingkey,在控制台设定bindingkey。
Topic
routingingkey可以是多个单次的列表
- #:指代0个或多个单次
- *:指代一个单词
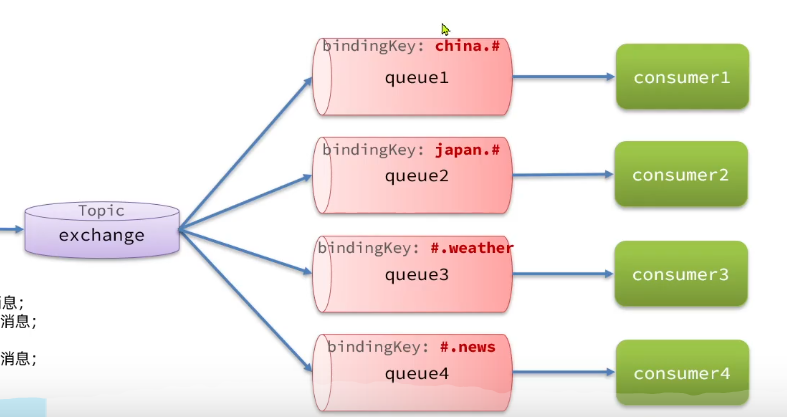
(若是#.#就是会关注所有新闻
更加灵活方便
声明队列和交换机–替换控制台操作
1.@Bean
2.@RabbitListener、@QueueBinding、@Queue、@Exchange
消息转换器
安全问题。发消息:采用Jackson转换器而不是jdk的。
消息丢失现象?
MQ高级
可靠性解决,三个阶段:发送者、MQ、消费者的可靠性
发送者可靠性
1.生产者重连:
由于网络波动,出现客户端连接MQ失败的情况。
通过配置文件,配置超时时间,开启超时重试机制……
*阻塞式重试:影响性能 配置合理等待时长和重试次数
2.生产者确认
PublisherConfirm和PublisherReturn两种确认机制
PublisherConfirmType:none、simple、correlated

PublisherReturnType:turn 编写回调函数(基于future)

MQ可靠性
–默认在内存里面,容易出现消息丢失。
–内存空间有限,消息积压,MQ阻塞(pageout),新的发不进去–>到磁盘
1.数据持久化
- 交换机持久化 持久/临时
- 队列持久化
spring默认交换机和队列持久化
- 消息持久化 设置deliver_model
2.LazyQueue
惰性队列,消费者消费时才会从磁盘读取到内存
x-queue-mode参数为lazy–>控制台
Java代码加arguments @Agruments即可
总结

消费者可靠性
消费者确认机制
–消费者处理完了消息,应该告诉MQ自己执行完了
- 返回ACK MQ可以删除
- 返回Nack 再次投递(消息本身没有问题
- 处理失败 拒绝该消息 Reject
- 消息本身有问题,再发送也处理不了
*类比事务执行
在spring配置文件里面配置,会自动监控和判断异常
失败重试机制
真要要失败了一直投递吗(nack
当然不是,现在本地重试,也是在配置文件里面配置,最大重试次数>消息会被删除/?
- RejectAndRequeueRecover:直接删除
- ImmediateRequeueRecover:nack重新入队
- RepublishMessageRequeueRecover:失败消息投递到交换机,通知人类处理
- 定义一个接收失败消息的交换机
- 定义RepublishMessageRequeueRecover
总结

业务幂等性
万一成功了却没有收到通知,被投递多次,消费者重复消费消息。
函数表达f(x)=f(f(x)) 即使重复执行,结果也不会改变。例如绝对函数。
幂等业务,一次或多次对业务状态影响是一致的
例如:查询,删除vs下单(非幂等
*表单重复提交 (token令牌机制,前端,
- 给消息加唯一id
- 业务判断(???乐观锁
(业务判断)如果出现并行修改,业务–>sql语句判断
*虽然上述方案能够保证99.99的成功,如果失败,兜底方案:error交换机人工介入,还有什么?
设置定时任务,定期查询订单支付状态。
延迟消息
延迟消息是指:生产者发送消息时指定一个时间,消费者不会立即收到消息,而是在指定时间后才收到消息
场景:5min之后去执行消息,看你支付没有
死信交换机
- nack 和 reject 成为死信 并且requeue为false
- 过期了,超时无人消费
- 满了,队积满了,最早的可能成为死信
DLE来实现上述场景,模拟延迟消息的效果
延迟消息插件
自动实现延迟生效
docker安装
如何使用:@Exchange注解 delay=”true” setDelay(5000)
取消超时订单
30=n*(<30)拆分 延迟时间发完了就取消订单,没发完就获取下一次的延迟时间,去看有没有支付订单
定义延迟时间的数组。实体。
发表回复