
简介
介绍
什么是消息:
统计用户在网站的操作,点击任意一个🔗都会被采集到
统计消息,临时存储,一个通信的管道
为什么叫kafka 喜欢的作者
消息队列的中间件:消息队列的组件
场景
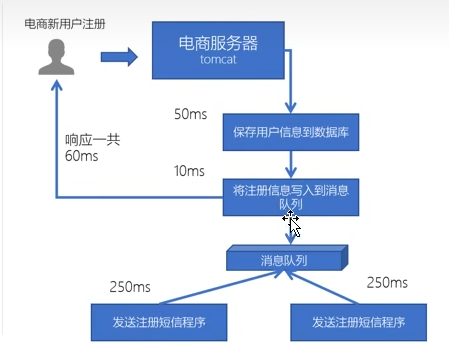
异步处理。下单之后邮件通知,注册短信等一系列操作。如果并行会非常耗时。
异步处理:
将比较耗时的操作放在其它系统里面,通过消息队列将需要处理的信息进行存储
例如发邮件,短信验证等
系统解耦:
订单系统-》消息队列-》库存系统
原来一个微服务是通过接口来调用另一个微服务,耦合严重。
把消息放在一个管道(消息队列里面去,放与取即可
流量削峰:
双十一,高吞吐
日志处理:
大数据领域常见,直接把用户操作通过服务器存在文件
用户–》web服务器–》消息队列–》Flink程序–》计算结果
生产者消费者模型
交互模型:先类比
HTTP请求 响应模型
数据库请求响应模型JDBC 基于MySQL的通信协议
在消息队列中变为生产者消费模型:如下
生产者*n–>📥=====消息队列=====📤<–消费者
1.点对点模式:
一个发送只有一个消费者,消费了就删除
发送者与接收者之间没有依赖性,互不影响
接收者成功接收之后需要应答,以便消息的删除
2.发布订阅模式:
源源不断放在消息队列,每个消息可以有很多个消费者(订阅者
有时间依赖性
需要订阅,提前订阅,保持在线
Kafka
围绕 发布与订阅/存储/处理 来讲解
对比rabbitmq的优点:消息延迟毫秒级,单机吞吐量十万级,可用性非常高(分布式而不是主从,消息理论上不会丢失
哪些公司在用:腾讯、微软、华为,等等
安装、搭建集群、环境搭建、一键启动脚本等…略
- 依赖zookeeper
- 每个节点时唯一传递 broker.id
- 配置数据存储目录
分区和副本是什么?
kafka有三层形式。Kafka有多个topic,每个主题有多个分区,每个分区又有多条消息
每个分区可以分不到不同的机器上:这样一来,从服务端来说,分区可以实现高伸缩性,以及负载均衡,动态调节能力。单个分区的时候,和顺序队列一样。
副本机制:每个分区可以有多个副本。这多个副本中,只有一个是leader,而其他的都是follower副本。仅有leader副本可以对外提供服务。目的就是冗余备份,且仅仅是冗余备份,所有的读写请求都是由leader副本进行处理的。follower副本仅有一个功能,那就是从leader副本拉取消息,尽量让自己跟leader副本的内容一致。
基础操作
topic:表需要表名,Kafka需要主题
#创建create
bin/kafka-topic.sh --create --bootstrap-server nodel.itcast.cn:9002 --topic test
#查看当前
bin/kafka-topic.sh --list --bootstrap-server nodel.itcast.cn:9002
#生产/消费测试脚本来读取标准输入/消费
bin/kafka-producer.sh --broker-list nodel.itcast.cn:9002 --topic test
bin/kafka-consumer.sh --bootstrap-server nodel.itcast.cn:9002 --topic test --from beginning
#from deginning 从头拉取消息开发时使用KafkaTool
- 浏览节点,分区,副本
- 创建/删除topic
- 浏览zookeeper中的数据
基准测试
可以有测试工具测试生产者和消费者
JAVA-API程序
同步生产消息到Kafka
- 导入pom列表
- 代码库
- 客户端
- 工具类
- slf4j
- log
- 配置文件log4j.properties 配置输出
- 创建包和类KafkaProduserTest 创建消息并发送到集群之中
- 创建用于连接Kafka的properties配置 指定服务器位置等
- 构建生产者对象 <key,value>
- 调用send发送消息
- 调用future.get等待响应
- 关闭生产者
消费者程序
offset(消息拉取到哪里了),key,value
- Kafka的消费者properties配置:
- 消费者组,将若干个消费者组织到一起,共同消费Kafka中topic的数据
- 每一个消费者需要指定一个组名
- 自动提交offset,提交时间间隔
- 拉取key、value数据的deserializer
- 创建消费者
- 订阅topic
- 循环,不断拉取数据
回调函数—异步方式生产消息
使用匿名内部类实现callback接口,该接口中表示Kafka服务器响应给客户端,会自动调用onCompletion方法
metadata:元数据
exception:如果为空,发送成功。如果不为空就失败,有失败信息。
Kafka结构
——Kafka集群——-============
broker-0 进程 || Zoo- ||
broker-1 进程 || Keeper || 保存一些元数据隐私政策
broker-2 进程 || 集群 || 使用Kafkatool能够看到
————————===========
- 一个集群由多个broker组成 实现负载均衡和容错
- broker是无状态的,通过zookeeper来维护
- 每个broker都可以处理tb消息而不影响性能
zookeeper:
用于管理和协调broker,并且存储了Kafka的元数据(多少个topic、partition、consumer
ZK用来通知P和C有新的broker加入,或者通知又出现故障的B
什么是partition 区
B–>(TOPIC)–>P–>CG–>C1 C2 C3
副本可以确保某个服务器故障时,数据依然可用
Kafka数据不能做修改 旧———–>新
topic是逻辑结构,是写在每一个分区里面的
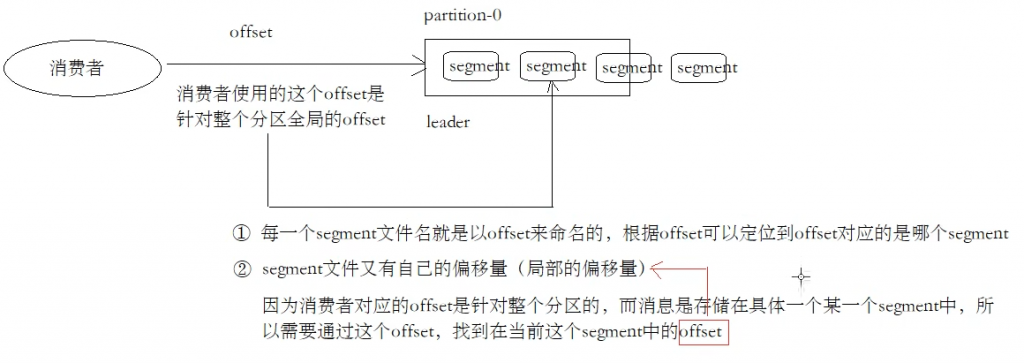
offset:
每个partition都有很多数据,关于拉取数据,消费者/组应该记住拉取到哪里了
- offset记录着下一条要发送给consumer的消息序列号
- 默认存储在zk 自动提交offset:enable.auto.commit
- offset只在分区中才有意义,分区间没有意义
- 每一个分区中消息是有顺序的,有一个id,这个就是offset
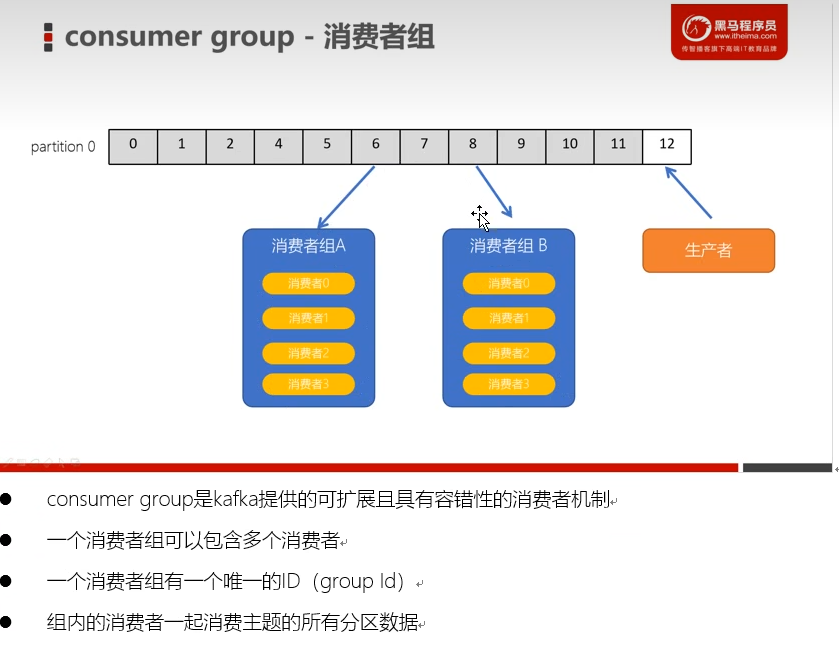
消费者组CG:
- 每一个消费组有一个唯一的名字。配置groupid一样的消费组属于同一个组
- 一个消费组中可以包含多个消费者,共同来消费topic中的数据
- 一个topic中如果只有一个分区,那么只能被某个组中的一个消费者消费。
- 有多少个分区,就可以被同一个人租内的多少个消费者消费 1v1
幂等性与事务
幂等性原理
若Kafka没有幂等性(ack响应失败,但其实已经保存了,出现retry就可能在partition中存入重复的消息
幂等性需要配置
props.put("enable.idempotence",true)引入了produser id PID 和sequence number的概念
- 每个produser在初始化的时候会分配一个唯一的PID,对用户是透明的
- SN:从0开始递增的,发送到指定主题分区的消息对应一个SN。若seqn=0,<=pid对应的seq,说明以前已经存过了
避免生产重复的消息去保存
Kafka高级
生产者分区写入策略
轮询分区策略(默认、负载均衡,key为空,乱序)
随机分区策略(不用,乱序)
按key分区策略(注意出现数据倾斜,局部有序)
自定义分区策略(创建自定义分区器
乱序问题
按分区来看,若一段连续的数据,使用轮询算法,为了保证负载均衡,数据会被打散。所以,Kafka的有序,是每个分区的有序。若只用一个区,就失去了分布式的意义。
消费者组rebalance机制
再均衡机制,某些情况下,消费者消费的分区会产生变化(比如某个P崩溃了,一个消费者当前没有分区要削峰)导致消费者分配不均匀,去均衡消费者消费的分区
触发时机
- 消费者数量发生变化
- topic发生变化
- partition数量
有不良影响,rebalance时,所有消费者都会停止,直到每个消费者都已经被分配所需要消费的分区为止
消费者分区分配机制
-Range范围分配策略(默认,是一个范围,保证每一个消费者消费的是均衡的,*Range的范围分配策略是针对每个Topic,不是全局,某个Topic的哪几个分区
n=分区数量/消费者数量
m=分区数量%消费者数量
前m个消费者,每一个消费n+1个
剩余消费者消费n
-轮询RoundRobin策略
所有topic的分区先排序,hashcode,然后来轮询
-粘性Stricky分配
1.尽可能均匀
2.发生rebalance,分区的分配经可能与上一次相同
3.没发生rebalance时,和轮询类似
副本的ACK机制
producer不断写数据给Kafka,数据是否写入成功,就会有一个对应ACKs参数配置。
1、ack为0 不管返回。性能最好。数据可能丢失
2、ack为1 等待leader确认接收(返回成功)之后,才会发送下一条数据,性能中等。一个分区只能有一个leader,保证拉取的数据一致。
3、ack=-1 or all 等到所有副本同步leader的数据成功才会发送下一条。性能最慢。能够保证数据不丢失。
*根据业务情况来选择ACKs。一部分数据丢失不会有影响,可以选择0/1.若数据一定不能丢失就配置-1/all
*分区中有 leader和follower 根据分区来。???为了确保消费者消费的数据是一致的。只能从leader去读取数据。follower只能备份不能操作数据。
*👆意义:follower可能会被选举为leader!!!针对分区。一个分区只会有一个leader。
high level API & low level API
高级API
不需要管理offset,也不需要管理分区,副本。由Kafka统一管理。rebalance。
无需关注底层逻辑,开发简单。
自动根据ZK中保存的offset来读取数据。
不能自己控制,无法做到细粒度的控制
低级API
可以自己存储offset。自己控制offset。
指定消费者拉取某个分区的消息👇👇👇可以做到细粒度的控制
手动消费分区数据
- 某些时候需要指定分区。将指定分区保存到外部存储
- 某个程序是高可用的。出现故障重启。从指定分区重新消费数据。
不使用subscribe订阅而是assign方法指定消费消息。
注意:Kafka的协调不在起作用。失效。没有rebalance。
监控工具 Kafka-eagle
/////略
Kafka原理
分区的leader和follower
leader和follower
针对分区而不是broker
- leader负责处理读写操作,而follower只负责副本数据的同步
- 如果leader出现故障,其它follower会被重新选举为leader
- follower会像consumer一样拉取leader的数据
*ZK的follower可以读
*一个topic有多个分区,同样可以实现负载均衡
ar、isr、osr
实际环境中leader会出现故障,所以会选举出来新的leader。投票(redis。Kafka希望我们快速选举出来leader,所以把follower可以按照不同状态分为三类
*ZK选举要投票,创建临时节点(慢,废弃
- AR已分配的副本 分区所有副本称为【AR】
- ISR所有与leader副本保持一定程度同步的副本
- OSR 表示不同步的
AR=ISR+OSR=leader+follower+follower+… 正常情况下,OSR为空
controller介绍与leader选举
controller
- Kafka启动时会在所有broker中选择一个controller
- controller是根据broker来的
- 其它的broker会注册该节点的监视器
- controller也是高可用的,某个controller崩溃,其他的broker会注册为controller
controller选举leader
通过RPC,过程调用,通知broker
controller读取当前分区的ISR 只要有一个副本replica幸存,就会被选为leader,否则leader=-1 快速选举
leader的负载均衡
如果某个broker crash之后会导致leader分别配不均:一个broker上存在一个topic下不同partition的leader
有指令代码
读写流程
找到leader在哪 从zookeeper/broker/topics/主题名/分区名/state
leader将消息写到本地log,顺序写
拉模式(√,推模式(rabbitMQ

Kafka的物理存储
以partition为单位
topic(partition0(segment(log index timeindex)) partition1 partition2)

消息不丢失(面试常问,待总结
broker
生产者
消费者
。。。。。。
数据积压
外部业务外部IO
内部异常:宁可积压也不愿意数据丢了,没有消费成功最好不要提交offset
所以企业要有监控系统
数据清理
定期清理(因为是临时的 日志删除/压缩
配置log.cleanup,×××
可以设置阈值等
时间、空间概念上的阈值
发表回复